おなじ「かみ」でも「髪」が抜けるのは困ります・・
こんな本を読んでみました
ふだんは政治家さんが書いた本は読まないのですが、ひょんなことから今回手に取りました。
(すぐ売ると思うので、紙の本で購入)

・日本のデジタル化はどんな感じなのか
・デジタル化を進める上での諸課題
に興味があり、そのへんも書かれていました。
日本(人)の特徴が、「デジタル化においては」いろいろ悩ましい。
以前から思っていたことですが、これを踏まえてどう進めるのか?
なんだろうと思います。
デジタル化が必ずしも「是」ではないと思いますが、多くの部分でデジタル化の方向に行かざるを得ない現実があります。
そういう意味では、いろいろ考えを進めることができました。
住所と氏名と用語
この本で、3つ「そうだよなー」と思いつつ、これがどこまでできるのかな?
と感じたものが、住所と氏名と用語です。
この本によれば、行政側でデータ化を進めるにあたり、まず「どこの」「だれ」に着手するわけですが、これが大変。
本の内容からざっくり書くと、
まず「どこの」の住所。
・1-2-3、1丁目2番地3号、1丁目2番3 は同じ?
・日本の住所管理は、町字情報、住居表示情報は市区町村
・地番は登記所で管理
・京都の住所(上る、下るというような独特の表記)
これらは、現在郵便局や宅配便の方のマンパワー(奉仕とスキル)で解決されています。
これを例えばドローンで配達するときにどうするか?
人間対応の場合は、2次元情報(地図的情報)で足りますが、機械だと3次元情報(緯度、経度、高度)が必要になります。
建物の大きさや玄関口はさまざまですから、これをプロットした情報は難しそうです。
人間の力と組み合わせ?になるのかと思います。
次に「だれ」の名前。
・漢字、フリガナ問題
・表記の揺れ、読み方
・名前の読み方「羽生さん」(はにゅうさん?はぶさん?)、「山崎さん」(やまざきさん?やまさきさん?)
・「海」と書いて「まりん」ちゃんだったり
・渡辺さんの「辺」(「邉」などたくさん種類があります)
欧米では、アルファベット26文字と数字10個の組み合わせで、表されます。
デビットさんもデイビットさんもデヴィットさんも、David です。
漢字(旧字含む)、ひらがな、カタカナ、ローマ字、全角半角と多彩な文字を操る日本人。
デジタル化は、なじまないのかもしれません。
これを解決するのは、ナンバリングでしょう。
ただし、漢字、ひらがな、カタカナに番号をつけるとすごい数になりますから、「人」に番号をつけるマイナンバーは、ある意味優れたしくみです。
ひらがなで書こうが、カタカナで書こうが、その「人」は特定できます。
人口の分の番号で済みます。
次に「用語」
これは私も日々感じているところです。
この本では「雇用者」を例に上げていましたが、この「雇用者」が役所や法律によってその意味するところ(範囲)が違う。
そうすると、AさんとBさんが同じ「雇用者」という言葉を使っていても、AさんとBさんの「雇用者」の範囲(認識)にズレが生じてしまいます。
話が噛み合わない、ズレの部分が抜け落ちることが起きてしまいます。
どこのだれ、用語の意味。
この簡単そうで基本的なもの。
これが「デジタル化においては」ものすごい難所なんだとつくづく感じました。
逆に言うと、これを今は「日本(人)の勤勉真面目なるマンパワー」で回している。
ここに対する「考え方」「認識」の道筋が見えてくると、一気に進むのかもしれません。
紙をデジタルに入れ込まない
時々書いていますが、ぜひやめてもらいたい、紙の入れ込みを改めてご紹介。
いつも引き合いに出す社会保険の用紙。
「糸氏エクセル」です。
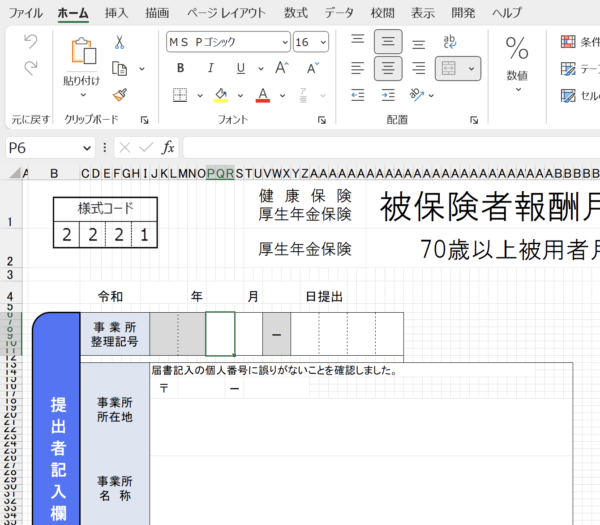
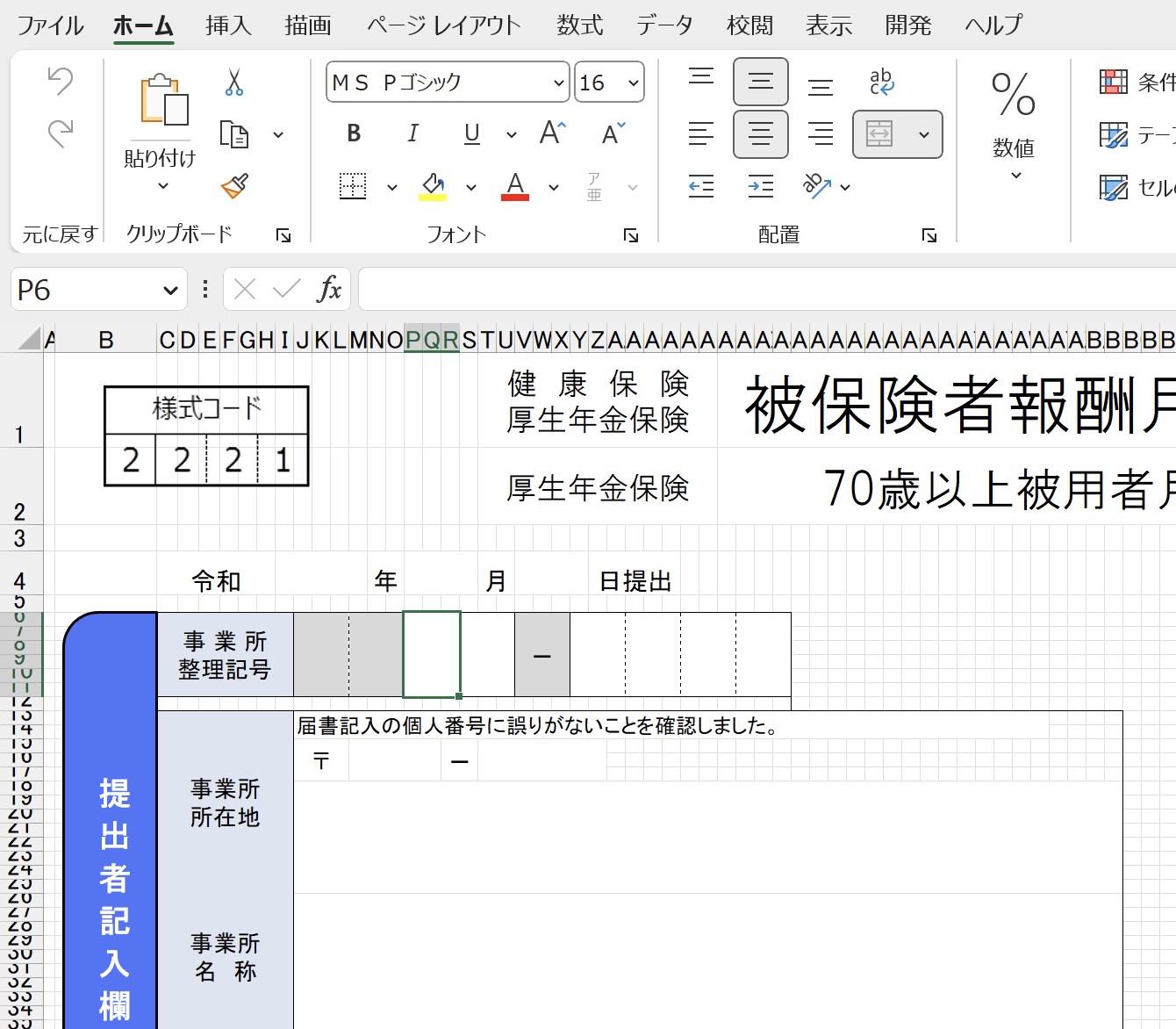
エクセルシートを方眼紙のように加工し、そこに紙の書式をねじ込んだものです。
私に作れと命ぜられたら、100%途中でくじけます。
これでも驚きなのに、さらにすごい加工が施されています。
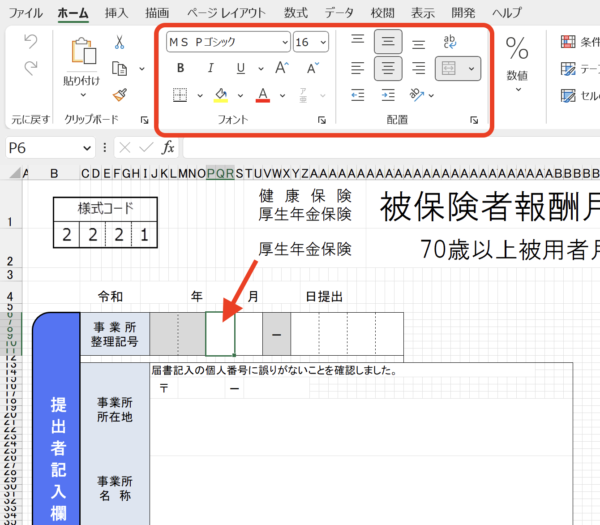
番号を入れるための結合されたセルの書式は、サイズが16で、中央揃え(センタリング)設定がされています。
一方で事業所所在地を入れる結合されたセルの書式は、
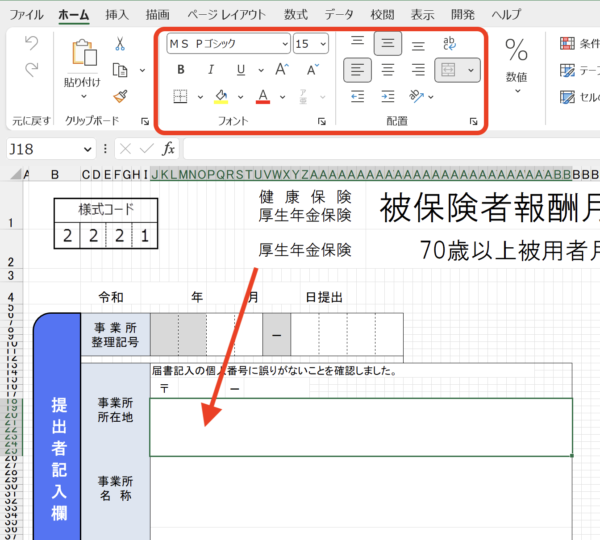
サイズが15で左寄せです。
糸氏エクセル、もはや「ネ申」がかっています。
でもこれは、やってはダメです。
この用紙がない状態から、手続きをネットで進めるには?
で考えていく必要があると思います。
e-taxもそうですが、多くのネット手続きでされているように、
・必要事項をフォームなどで入力
・ → プレビューで確認
・ → 送信
この流れを作って「糸氏エクセル」をなくしていくのがいいと思います。
まさか、この「用紙」をOCRで読み取るためにこの「書式」が必要、なんてことはないと思いますが、早くこの手のものは、無くしてほしいものです。
ーーー